
刚刚,DeepSeek宣布正式推出DeepSeek-V3.1模型,这是一次重大升级,旨在通过创新的混合推理架构、更高的思考效率和更强的智能体能力,为用户提供更高效、更灵活的AI解决方案。本次升级已在官方App、网页端及API平台同步上线,标志着DeepSeek在人工智能领域向“Agent时代”迈出了重要一步。
DeepSeek-V3.1的核心亮点在于其独特的“混合推理架构”,该架构允许一个模型同时支持“思考模式”和“非思考模式”。用户可以通过官方App或网页端的“深度思考”按钮自由切换模式,实现更智能的交互体验。在思考模式下,模型能显著缩短响应时间,相比前代DeepSeek-R1-0528,DeepSeek-V3.1-Think在输出token减少20%-50%的情况下,保持了相同的任务表现。这一效率提升得益于思维链压缩训练,有效优化了资源消耗。
在各项评测指标得分基本持平的情况下(AIME 2015: 87.5/88.4, GPQA: 81/80.1, liveCodeBench: 73.3/74.8),R1-0528 与 V3.1-Think 的 token 消耗量对比图:
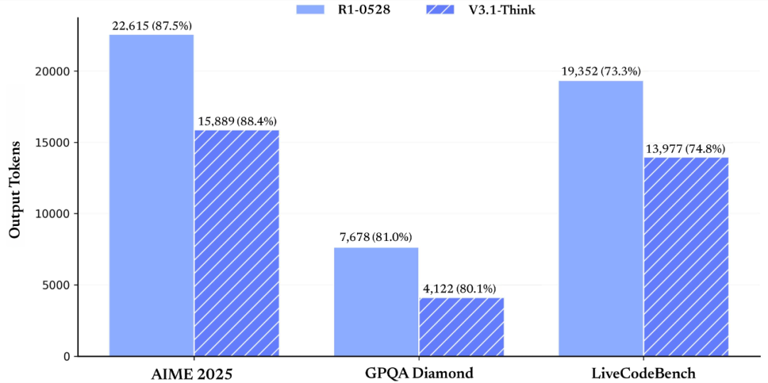
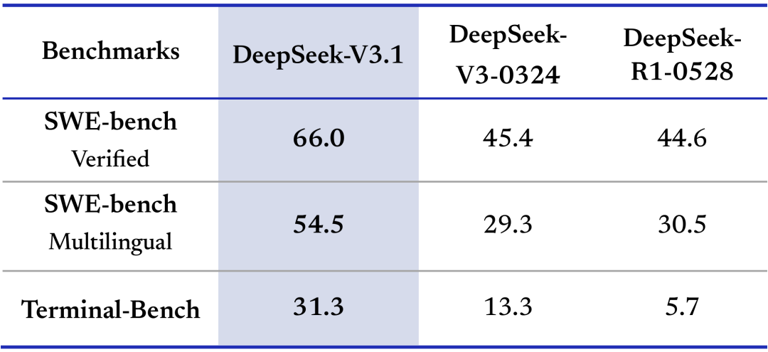
此外,DeepSeek-V3.1在智能体能力上实现了质的飞跃。通过Post-Training优化,模型在工具使用和智能体任务中的表现大幅提升。编程智能体方面,在代码修复测评SWE与命令行终端环境下的复杂任务(Terminal-Bench)测试中,DeepSeek-V3.1相比前代模型有显著进步,所需轮数更少。
表 1:编程智能体测评(SWE 使用内部框架测评,相比开源框架 OpenHands 所需轮数更少;Terminal Bench 使用官方 Terminus 1 framework):
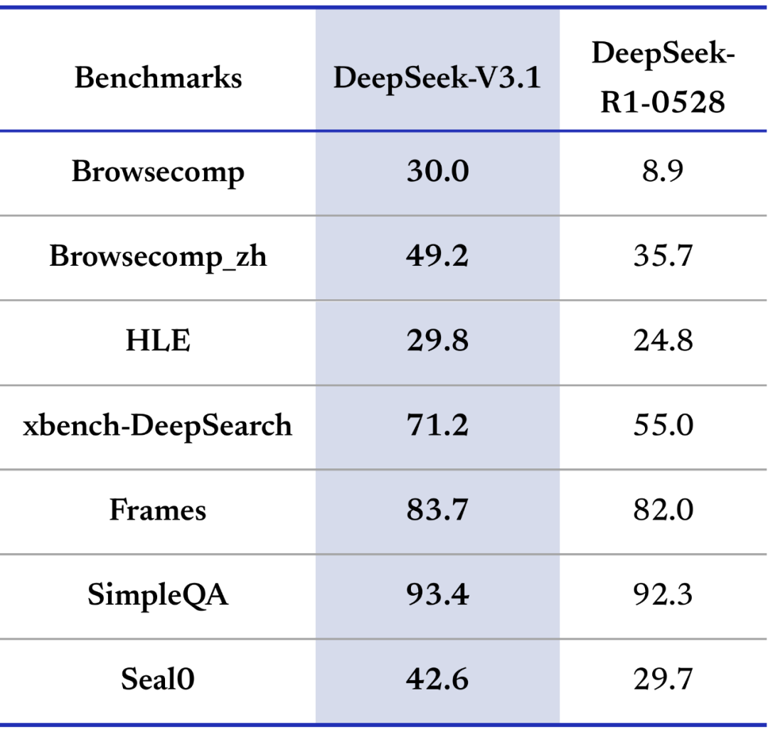
搜索智能体能力同样得到增强,在需要多步推理的复杂搜索测试(browsecomp)与多学科专家级难题测试(HLE)上,DeepSeek-V3.1性能已大幅领先R1-0528。
表 2:搜索智能体测评(测试结果调用商用搜索引擎 API+网页过滤+128K context window;R1-0528 使用内部 workflow 模式测试;HLE 测试同时使用 python 与 search 工具):
API方面,DeepSeek平台已全面升级:deepseek-chat对应非思考模式,deepseek-reasoner对应思考模式,上下文窗口扩展至128K。同时,API Beta接口支持了strict模式的Function Calling,确保输出符合schema定义(详见官方文档)。新模型还增加了对Anthropic API格式的支持,便于用户将DeepSeek-V3.1集成到Claude Code框架中。
在开源策略上,DeepSeek-V3.1的Base模型和后训练模型已在Hugging Face和魔搭平台开源。Base模型基于V3进行了840B tokens的外扩训练,后训练模型则针对推理优化。需要注意的是,V3.1采用了UE8M0 FP8 Scale参数精度,并对分词器及chat template进行了调整,建议部署用户参考新版说明文档。
价格政策方面,DeepSeek将于北京时间2025年9月6日凌晨起调整API接口调用价格,执行新版价格表并取消夜间时段优惠。在9月6日前,所有API服务仍按原价格计费。为满足用户需求,平台已扩容服务资源。
【新闻来源】 金融界财经 http://u5a.cn/Ex31R
(本网转发此文章,旨在为读者提供更多的信息资讯,所涉内容不构成投资、消费建议。文章事实如有疑问,请与有关方核实,文章观点非本网观点,仅供读者参考。)